
Data analytics success relies on providing end-users with quick access to accurate and quality data assets. Companies need a high-performing and cost-effective data architecture that allows users to access data on demand while also providing IT with data governance and management capabilities.
At SoftKraft we help clients leverage cloud-native technologies to capture, analyze, and share growing volumes of customer data for advanced analytics, and machine learning.
In this article, you will learn how to implement a Master Data Management solution using AWS. Let’s start with defining what is MDM and its benefits.
What is Master Data Management?
As a discipline, MDM is heavily related to data governance principles, with the goal of creating a trusted and authoritative view of a company's data model.
As a technology, MDM solution automates the governance, management, and sharing of sensitive data across applications used by lines of business, brands, departments, and organizations. To create master records, MDM applies data integration, reconciliation, enrichment, quality, and governance to create master data, a "single source of the truth".
Master Data Management benefits
Managing multiple sources of information is a common problem, especially in large organizations. Costs associated with them can be significant.
Because data changes over time, it's easy for reference data to become out of sync, fragmented, inaccurate, and inconsistent. Business users lose faith in it as it deteriorates.
This creates the need for a “golden record” a single, well-defined version of all the data entities in an organizational ecosystem.
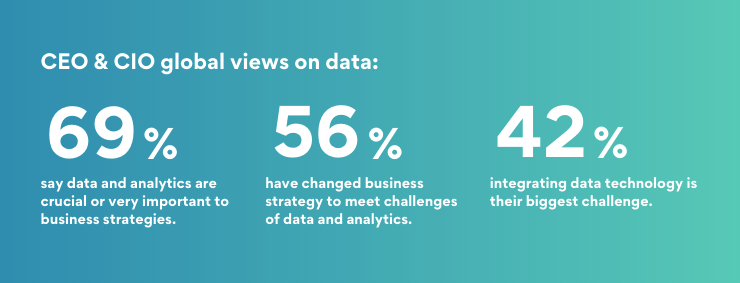
Even if your organization doesn't have a formal master data management solution, chances are good that your data warehouse, CRM, or ERP systems are using some form of master data management. As the trend toward decentralized data analysis continues, we see a few forces at work that support the case for incorporating master data management into your organization's strategic plan.
Common MDM solution benefits include:
A single view of your data
Bringing together data from disparate systems and creating master data helps solve business problems faster, identify new opportunities, and improve machine learning model accuracy. This single view is flexible enough to drive your operational business process as well.

MDM helps you manage risks, threats, improve company processes, manage privacy, reduce labor costs, optimize processes, and execute customer care programs.
Business impact
- Identify and act on insights faster
- Business agility in the face of shifting markets and unique customer needs
- More accurate inside and outside reporting with less data security risks
Democratization of Data Analysis
Businesses users are increasingly responsible for developing their own data value hypothesis (and modeling their own data) and they need to be autonomously doing so with highly accessible and capable self-service analytical tools.
Data entity resolution tasks such as entity resolution, standardizing, deduplicating, cleansing are often the most difficult, time-consuming, and error-prone.
Users can gain business insights faster and cheaper if they have master data that is easier to blend, analyze, interpret, and trust.
Business impact
- Shifting to a data-as-a-service model
- Monitoring customer information
- Efficiencies in the workplace
- Customer journey analytics

Increased Machine Learning Potential
Businesses investing in data science and machine learning are quickly discovering that a lack of usable machine learning training data limits their optimization potential. This is usually due to poor data collection and/or inconsistent business process execution (e.g. human error, governance). MDM can help you to integrate data required for your business needs.
Business impact
- Revenue growth
- Improving customer service
- Providing personalized marketing
- Supply chain efficiency
Why migrate MDM to AWS?
Keep in mind that the master data management solution is dedicated primarily to transactional data sources used in organizations. However, regardless of the transactional data focus of MDM, AWS data lake technologies can be successfully used to implement MDM data flow.
Cloud has become the new normal as businesses of all sizes realize its benefits. For most organizations, the question is “how quickly can we move?” “What do we move first?”
We have created the recipe for the right AWS infrastructure, deployment, and operational models for MDM:
- MDM on AWS makes use of cloud-native Infrastructure as Code frameworks to quickly deploy and execute new workloads while avoiding human error. AWS Config, CloudWatch, and CloudTrail are examples of technologies that audit events and identify opportunities for operational improvement.
- Flexible instance management allows you to save money by turning off environments when they aren't in use. On average, migrating to AWS saves organizations 31% in infrastructure costs compared to on-premise hosting.
- MDM is deployed in a secure HIPAA-ready environment where access to data is restricted and audited. AWS native services keep track of Who, When, Where, and What data was accessed, as well as ensure that all data is encrypted both in transit and at rest.
AWS Master Data Management solution architecture
MDM involves the use of a number of different technologies. Understanding those technologies, as well as learning how to effectively integrate them, is essential.
A data lake on Amazon Web Services (AWS) is the best way to achieve data management excellence because it captures and makes quality data available to analysts in a timely and cost-effective manner.

Data Sources
The data can come from many different sources, and the data lake should be able to handle the volume of data that is being received.
The following are some of the sources:
- OLTP systems like Oracle
- SQL Server, MySQL, or any RDBMS
- File formats like CSV, JSON, XML
- IoT Streaming data
Data Ingestion
Collecting and processing the incoming data from various data sources is the critical part of data lake implementation. This is the most time and resource-intensive step.
Tools
AWS offers a variety of highly scalable managed services for building large data pipelines:
AWS Data Pipeline allows you to create a batch and streaming data pipelines. It is tightly integrated with Amazon Redshift, Amazon Dynamo, Amazon S3, and Amazon EMR.
AWS Glue is a fully managed ETL service that allows engineers to quickly build data pipelines for analytics. You can create data pipelines in a few clicks! It automatically discovers and catalogs data using AWS Glue.
AWS EMR is a managed Hadoop/Spark cloud service. AWS EMR can be used for many things: build data pipelines using Spark, moving an existing Hadoop environment to the cloud.
Raw data layer
Raw data storage is important for the implementation of any data lake. Using AWS S3 you can create a highly scalable and highly available data lake raw layer, which also offers extremely high service level agreements (SLAs).
Additionally, it includes a variety of storage classes, including S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA, S3 One Zone-IA, and S3 Glacier, which are used to address a variety of use cases and SLA requirements.
Consumption layer
All of the preceding items are internal to the data lake and will not be accessible to external users. The consumption layer is where you store curated and processed data that is made available to end users. Reports, web applications, data extracts, and APIs are all examples of end user applications.
Several criteria were considered when selecting a database for the consumption layer:
- Size of the data
- Data retrieval patterns, such as whether applications use analytical queries, such as aggregations and computations, or simply retrieve data based on some filtering
- Data ingestion, whether in large batches or in high-throughput writes (i.e. IoT data streaming)
- Whether the data is structured, semi-structured, quasi-structured or unstructured
Tools
Amazon Dynamo is a distributed NoSQL database with a large number of columns that can be used by applications that require consistent performance and millisecond latency at any scale. It is completely managed and is suitable for document and large column data models. Additionally, it supports a flexible schema and is suitable for use in web, ecommerce, streaming, gaming, and IoT applications.
Amazon Redshift is a high-performance, fully managed data warehouse database service that scales to petabytes of data. It utilizes a standard SQL interface, allowing organizations to continue to use their existing business intelligence and reporting tools. Amazon Redshift is a columnar database that is distributed across multiple nodes. This enables parallel processing of requests across multiple nodes.
Amazon DocumentDB is a managed document-oriented database service that supports workloads involving JSON data. It is compatible with MongoDB. It's fast, highly available, and scales well when dealing with massive amounts of data.
Machine Learning and Data Science
Machine learning and data science teams are the data lake's primary consumers. They use this data to train and forecast their models, as well as to apply the trained models to future data variables.
Tools
Amazon Glue Please refer above
Amazon EMR Please refer above
Amazon SageMaker enables the rapid development, training, and deployment of machine learning models at scale, as well as the creation of custom models with support for all popular open-source frameworks.
Amazon has a huge set of ML and AI tools. Additionally, it offers pre-trained AI services for computer vision, natural language processing, recommendation engines, and forecasting.
Data Governance
Master data governance is a wide subject. It involves a variety of tasks, including data security and identity and access management, discovery, data lineage, and auditing.
Tools
Amazon Glue Catalog is a fully managed metadata management service that integrates seamlessly with other Amazon Web Services components such as Data Pipelines and Amazon S3. You can easily discover, comprehend, and manage data stored in a data lake.
Amazon CloudSearch is a type of enterprise search tool that enables you to locate information quickly, easily, and securely.
AWS Identity and Access Management (IAM) provides fine-grained access control across all of AWS. With IAM, you have more control over who can access what services and resources.
AWS KMS is a cloud-based key management service that enables us to manage encryption keys in the cloud. You can generate/create, rotate, use, and destroy AES256 encryption keys in the same way that we do in our on-premises environments. And using REST API can encrypt and decrypt data.
Data Operations
Managing and supporting master data lakes is essential. AWS provides several tools for this.
Tools
AWS CloudTrail monitors and records account activity across your AWS infrastructure, allowing you to maintain complete control over data storage, analysis, and remediation.
Amazon CloudWatch enables you to monitor, store and manage log files generated by Amazon Elastic Compute Cloud (Amazon EC2) instances, AWS CloudTrail, Route 53, and other sources. The audit log entries in these logs descrive "who did what, where, and when?" in relation to your AWS Cloud resources.
Best Practices for a Successful Data Lake Deployment
There are four major aspects that will determine the success of your data lake now and in the future.
Connect more data from more sources
A crucial component of a flexible data lake architecture is the ability to connect to a variety of new and existing data sources and to easily add them to the catalog as they become available.
If data must be imported directly from relational database management systems (RDBM), this can be accomplished by leveraging Sqoop within Amazon EMR and pulling the data in a highly distributed fashion.
As data is received, ensure that it is placed in the appropriate Amazon S3 zone for the remainder of the post-ingestion processing to occur.
A similar procedure is followed for streaming ingestion, except that an AWS native service such as Amazon Kinesis or Amazon MSK is used instead of Sqoop.
Catalog data for accurate and easy access
Users, data scientists, and data analysts can easily find and understand the datasets they need thanks to the description and organization of an organization's datasets.
Data catalog focus on automation and operationalization is a big advantage. It is possible to automate and repeat a large number of post-ingestion tasks to ensure that newly ingested data can be trusted by data consumers.
If AWS Glue is being used, any data collected within AWS Glue can be included in an AWS data lake, and any additional business, technical, and operational metadata can be supplemented with information gleaned from AWS Glue.
Ensure data security and traceability
Compliance with privacy and security regulations in the industry necessitates data governance that allows for role-based access control.
All processing is done on Amazon EMR, which serves as the compute layer in a governed data lake that uses zone-based Amazon S3 storage.
In order to perform any extract, load, and transform (ELT) processes on this data, use both Amazon EMR and AWS Glue. Amazon Athena can be used to query the finalized data.
Provide business users with self-service data access
A lot of data lake successful implementation lies in your business and end-users’ ability to access the master data in a self-service manner. The data catalog allows them to explore what data is in the data lake.
For example, data transformation and provisioning to a sandbox, an analytics environment, or a reporting environment. Users can conduct global searches across zones, projects, workflows, data quality rules, and transformations, as well as collaborate in shared workspaces.
This data provisioning could take the form of an Amazon S3 bucket, RDS database, EC2 instance, or even an Amazon Redshift instance, where the data will be processed or visualized.
AWS Reference Architecture Case Study
Let us consider a hypothetical example of an airline initiative to build master data management (MDM) to enhance the data platform by identifying unique travelers and duplicates in loyalty membership.
The steps for building this MDM solution on AWS:
Create basic data as a service for the most critical domains: flight, passenger, and loyalty, with the key tenet of separating storage and compute.
Use purpose-built databases and serverless architecture to deliver microservices and events for the operational data store. Customers can scale these serverless and fully managed services based on adoption.
Use open standards to build the data lake using the same data as the operational data platform. Use a read pattern schema to make raw and curated data accessible to all user roles.
Build standard enterprise data warehouse schemas and data marts in Amazon Redshift for known and well-used usage patterns. For ad-hoc operations, publish the data catalog and use Amazon Athena to analyze the data lake directly. Customers can also customize the data warehouse to their needs.
Use Amazon SageMaker to provide standard AI/ML models for customer segmentation and lifetime value. Customers can also use Amazon SageMaker to build their own models on top of the data.

Source: AWS Reference Architecture - Airline Data Platform
Conclusion
For many organizations, AWS services can become a complete master data management solution with superior regulatory compliance. But how does the migration procedure work? How can you get your team ready?
Depending on your business processes needs, you should consider a full AWS cloud migration, a hybrid-cloud option, or an on-premise solution backed by cloud-ready containers and AMS support services.
Don't try to do it alone. SoftKrat, as a veted data engineering company, can provide you with a cloud architect to assist you in your data integration project.





