
Companies are spending billions of dollars on AI, and this trend shows no signs of slowing down. In 2023, global spending on AI systems was estimated at $154 billion across all industries, with some analysts predicting that spending will surpass $300 billion in the next few years.
For developers, mastering AI development within robust frameworks like Django is becoming essential. Django’s scalability, rapid development capabilities, and strong security features make it an excellent choice for building AI-driven web applications. This comprehensive guide outlines seven proven best practices to master Django AI development, helping you leverage its powerful features to create high-performance AI-powered Django web applications.
- Why is Django a good choice for AI web development?
- 7 proven best practices for Django AI development
- 1. Speed up development with Django’s built-in features
- 2. Integrate AI services using dedicated frameworks
- 3. Leverage vector databases to store complex model data
- 4. Use RAG to train the model with business data
- 5. Load large data sets without atomic transactions
- 6. Use Celery async tasks for heavy data manipulation
- 7. Minimize database queries with bulk operations
- AI software development with SoftKraft
- Conclusion
Why is Django a good choice for AI web development?
Django is an excellent choice for development of AI web apps for several reasons:
- Integration with AI libraries: Seamlessly integrates with popular AI and machine learning libraries such as TensorFlow, PyTorch, and scikit-learn, which are essential for tasks such as data analysis and computer vision.
- Robust security: Provides strong protection against common web vulnerabilities, ensuring secure applications.
- API development: The Django Rest Framework simplifies the creation of APIs, which are often essential for artificial intelligence applications such as natural language processing.
- Community and support: Boasts a large, active community with extensive documentation and support.
- Rapid development: Encourages rapid development, allowing for faster implementation and scaling of AI projects.
7 proven best practices for Django AI development
Building AI solutions with Django can be highly effective, but it requires following certain best practices to maximize efficiency and performance. In this section, we'll explore seven expert tips that can help you leverage Django's features, integrate advanced AI functionalities, and optimize your development process for creating robust AI applications.
Speed up development with Django’s built-in features
Django, a high-level Python web framework, offers a range of built-in features that significantly speed up the development of AI web applications. Here’s how:
- Django admin: Django's admin interface allows for efficient data and model management without the need for custom backend code, enabling quick setup and monitoring of AI models.
- Authentication system: Django's built-in authentication system provides secure user management and authorization out of the box, ensuring that only authorized users can access and interact with sensitive AI functionalities.
- Form handling: Django simplifies input collection and validation through its form handling capabilities, allowing for easy integration of user inputs into AI workflows and ensuring data integrity.
- URL routing: Django’s URL routing system offers a flexible and organized way to define endpoints for various artificial intelligence functionalities, facilitating seamless navigation and interaction within the application.
- Static file management: Django’s templating engine enables the creation of dynamic and interactive user interfaces, allowing developers to effectively display AI-generated content and visualizations.
Integrate AI services using dedicated frameworks
Integrating AI services using dedicated frameworks can greatly enhance the functionality and user experience of Django web applications. By leveraging the Django Rest Framework, developers can build RESTful APIs that enable seamless communication between models and other applications. This capability allows for the creation of sophisticated AI-driven features within Django apps.
For instance, integrating OpenAI’s ChatGPT model can help develop interactive chatbots. By installing the OpenAI Python library and creating a Django view to handle request processing and response generation, experienced developers can build customized chatbot applications tailored for various purposes.
For more advanced AI solutions, frameworks like LlamaIndex provide an excellent foundation. LlamaIndex is designed for building context-augmented LLM applications, making it ideal for tasks such as question-answering chatbots, document understanding, and autonomous agents.
Leverage vector databases to store complex model data
Vector databases have become essential for handling tasks like similarity search and recommendation systems in AI applications. They allow for efficient storage and retrieval of high-dimensional vectors, which is crucial for applications such as image search and document similarity.
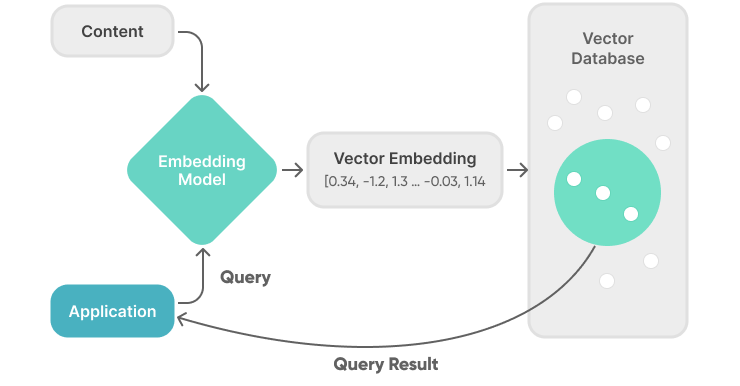
If you're using PostgreSQL, consider integrating pgvector, a PostgreSQL extension for vector similarity search. Pgvector allows you to store vectors directly in your database and perform similarity searches using SQL queries. Let’s look at an example of how this works.
Step 1: Install Django and pgvector
Connect to your PostgreSQL server as a superuser and execute the following command to install pgvector:
CREATE EXTENSION pgvector;Once pgvector is set up, you can integrate it into your Django project. This integration allows your web applications to perform complex AI tasks like similarity searches directly from the database.
Step 2: Define a Django model
Create a model in Django to store and manage your vector data. Here’s an example model that includes a name field and a vector field:
from django.db import models
from django.contrib.postgres.fields import ArrayField
class VectorModel(models.Model):
name = models.CharField(max_length=100)
vector = ArrayField(models.FloatField(), size=128)Step 3: Insert vectors
To insert vector data, you can use Django’s ORM:
VectorModel.objects.create(name="Example", vector=[0.1, 0.2, ..., 0.128])Step 4: Retrieve and search vectors
For searching similar vectors, perform a raw SQL query within Django to leverage pgvector's capabilities:
from django.db import connection
def search_similar_vectors(vector):
with connection.cursor() as cursor:
cursor.execute(""" SELECT name, vector FROM myapp_vectormodel
ORDER BY vector <-> %s
LIMIT 5;
""", [vector])
return cursor.fetchall()This function fetches the top 5 vectors closest to the input vector, utilizing pgvector's distance operator <->.
Step 5: Implement a search view
To make vector search available through your Django application, you can set up a view that handles vector search requests:
from django.http import JsonResponse
def vector_search(request):
input_vector = request.GET.getlist('vector', [])
input_vector = [float(i) for i in input_vector]
results = search_similar_vectors(input_vector)
return JsonResponse({"results": results})This view function retrieves vectors from a query parameter, performs a search, and returns the results in JSON format.
Use RAG to train the model with business data
One of the main hindrances to full adoption of AI is the risk of inaccurate responses and hallucinations. RAG provides businesses a way to achieve higher levels of AI trust by sourcing responses not just from the LLM, but through an external knowledge base of curated, company-specific data. The setup looks something like:
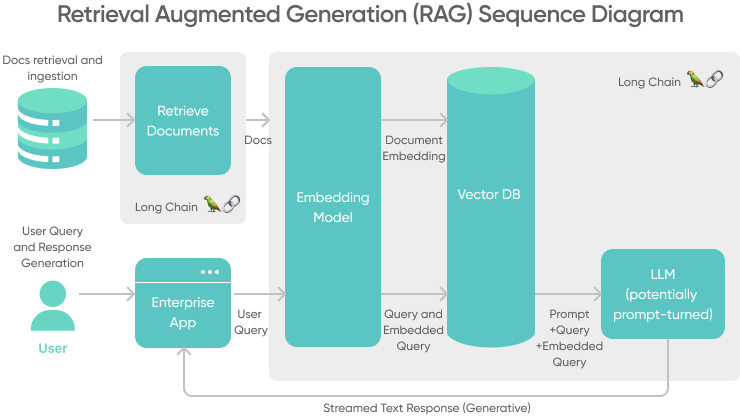
RAG allows you to build AI systems that:
- Access business-specific data: RAG allows AI systems to tap into extensive internal databases (like customer support documentation or product information), ensuring responses are informed by company-specific knowledge.
- Counter AI hallucinations: RAG effectively addresses AI hallucinations that often stem from reliance on flawed internal datasets. By using verified external data, it significantly improves the accuracy of AI responses and reduces misinformation.
- Enhance reliability and transparency: Applications developed with RAG can cite sources, providing greater reliability and accountability in AI-generated content.
Load large data sets without atomic transactions
When working with large datasets in AI web development scenarios, traditional methods of loading data can lead to performance issues. Using Django’s bulk_create method with a batch_size parameter may seem like a viable solution. And, it does allow you to load data without relying on atomic transactions, however, this approach runs all operations within a single database transaction, which can lead to severe issues such as import failure, performance bottlenecks, locking, concurrency problems, or even exhaustion of database resources.
To mitigate these risks, a more robust approach involves splitting the operations into multiple database transactions. To do this, you need to disable atomic transactions within your migrations and manage database updates manually by disabling autocommit. Here’s how you can achieve that:
from django.db import transaction, migrations
def import_people_records(apps, schema_editor):
Person = apps.get_model("people", "Person")
transaction.set_autocommit(False)
for batch in read_csv_file("people.csv", BATCH_SIZE):
Person.objects.bulk_create(
[
Person(
name=name,
email=email,
)
for name, email in batch
],
batch_size=BATCH_SIZE,
)
transaction.commit()
class Migration(migrations.Migration):
atomic = FalsePRO TIP: This approach does have a drawback. If an issue occurs during the migration (e.g., loss of database connection), only a portion of the records may be saved, potentially leading to partial data imports.
Despite this, the benefits of avoiding a single large transaction often outweigh this risk, especially when dealing with very large datasets.
Use Celery async tasks for heavy data manipulation
When developing a Django application that involves data manipulation, it’s crucial to manage this efficiently to ensure optimal performance, particularly with large datasets that are so common with AI solutions.
A key strategy is to handle these tasks asynchronously, which helps in preventing the blocking of the main application thread and maintaining the responsiveness of your web app. For such purposes, Django can use Celery, an asynchronous task queue based on distributed message passing.
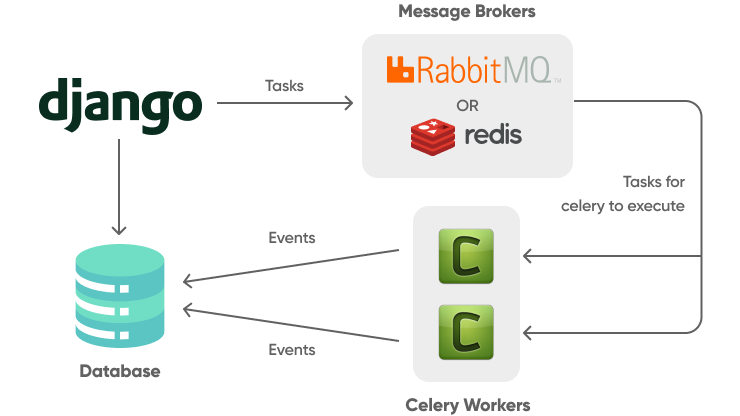
Here’s an example of celery task used to handle data manipulation task:
from celery import shared_task
from django.http import HttpResponse
from myapp.models import MyModel
@shared_task
def save_data_to_model(data):
instances = [MyModel(field1=item['field1'], field2=item['field2']) for item in data]
MyModel.objects.bulk_create(instances)
def some_view(request):
data = [{'field1': 1, 'field2': 'a'},{'field1': 2, 'field2': 'b'}]
save_data_to_model.delay(data)
return HttpResponse("Data is being processed!")In this example, save_data_to_model is a Celery task that processes data asynchronously. This task takes a list of dictionaries, each representing data to be stored in MyModel. This method efficiently handles larger datasets and leverages Django’s capabilities to interact with the database.
Celery can also be used to set up periodic tasks, third- party integrations like sending emails or notifications or long running processes that are resource intensive
For more details on setting up and configuring Celery in Django, refer to Celery’s documentation
Minimize database queries with bulk operations
Using bulk operations in an AI web application can significantly enhance performance and efficiency, especially when dealing with large datasets. Here are some tasks where you might want to use bulk operations:
- Data ingestion: When importing large datasets into your application, bulk operations can significantly speed up the process by reducing the number of individual database queries. This is essential for handling big data efficiently.
- Batch inference results storage: After running inference on a large batch of data, storing the results in your database using bulk operations ensures quick and efficient insertion, minimizing the performance overhead.
- Model training data preparation: Preparing and storing large volumes of training data often involves transforming raw data into a structured format. Bulk operations can expedite the insertion of these transformed datasets into your database.
- Logging and monitoring: AI applications generate a substantial amount of logs and monitoring data. Utilizing bulk insertions helps manage this data efficiently, ensuring that the logging system remains performant and does not become a bottleneck.
- Recommendation system updates: Updating the database with new recommendations or re-ranking existing ones can involve large datasets. Bulk operations streamline the handling of these large sets of recommendation data, enhancing the efficiency of your recommendation system.
AI software development with SoftKraft
If you're looking to develop a custom AI solution, consider our AI development services. Our python developers and AI experts will partner with you to build a comprehensive AI strategy. We'll assist you in selecting the most suitable technologies, seamlessly integrating them into your existing tech stack, and delivering a user-ready AI web app.

Conclusion
Incorporating these best practices into your Django web development workflow can provide a solid foundation for enhancing your application's performance, security, and scalability. By leveraging Django's built-in features, integrating cutting-edge AI services, and optimizing data handling, you can build powerful and reliable AI solutions. Stay committed to these practices to ensure your AI projects are both innovative and efficient.


